Software
Slacken
Slacken is improves on the Kraken 2 taxonomic binning algorithm. Being based on Apache Spark, it is highly scalable while implementing the original method very faithfully. Unlike Kraken 2, library size is not limited by total RAM. It also adds several new features not present in Kraken 2, among them dynamic minimizer libraries, which are built on the fly specifically for the samples being classified.
More information and source code is available in the GitHub repo.
See also the following post: Slacken: a super-scalable implementation of the Kraken 2 algorithm
A paper on Slacken was published in NAR Genomics and Bioinformatics:
Johan Nyström-Persson, Nishad Bapatdhar, and Samik Ghosh: Precise and scalable metagenomic profiling with sample- tailored minimizer libraries. NAR Genomics and Bioinformatics, Volume 7, Issue 2, June 2025, lqaf076, https://doi. org/10.1093/nargab/lqaf076
Discount
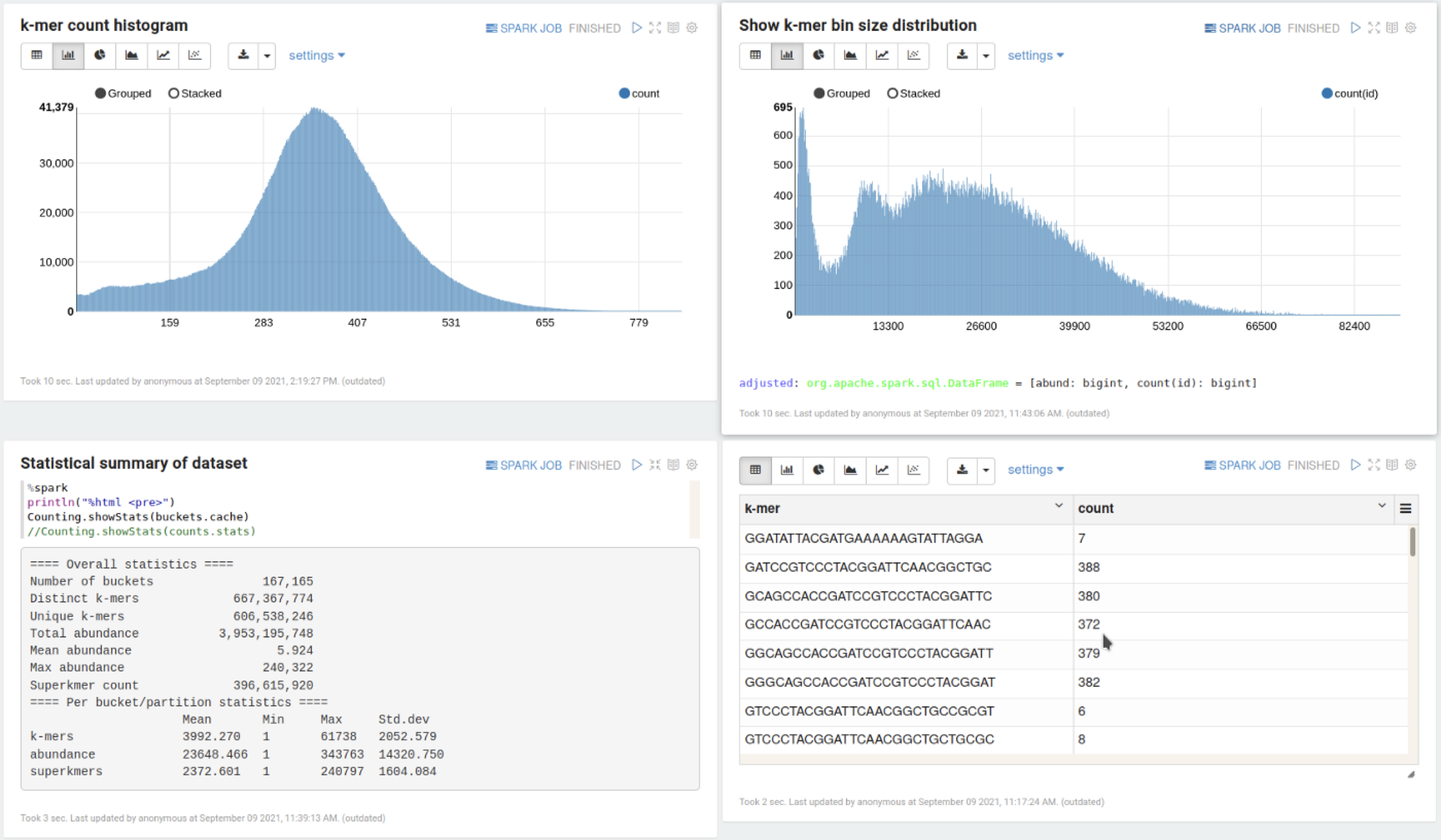
Genomic data can be subdivided into k-length fragments called k-mers, which can serve as a basis for other analyses such as genome assembly and taxonomic classification. Discount is a k-mer counter and analysis framework for Apache Spark, supporting interactive notebooks with Zeppelin. It scales to very large and complex data: to the best of our knowledge, it is the most efficient tool of its kind on Spark/HDFS. For more details, please see the GitHub repo.
A paper on Discount was published in Bioinformatics:
Johan Nyström-Persson, Gabriel Keeble-Gagnère, Niamat Zawad, Compact and evenly distributed k-mer binning for genomic sequences, Bioinformatics, Volume 37, Issue 17, 1 September 2021, Pages 2563–2569, https://doi.org/10.1093/ bioinformatics/btab156